AudioBuff
開いた瞬間から使える。8バンドEQ・ラウドネス正規化・高品質エクスポートに加え、Whisper による文字起こしまで全部ブラウザで。インストール不要。
すべてがブラウザの中に
プロの音声加工を、ダウンロードなしで。
ゼロインストール
ブラウザだけで完結。ダウンロード不要、アカウント不要。URLを開けばすぐ使える。
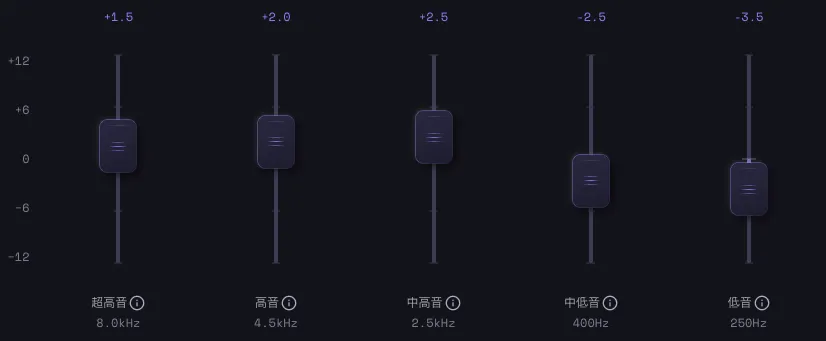
8バンドEQ
6バンドピーキング+ハイシェルフ+ローシェルフ。ハイパスフィルターも搭載。プリセットを選ぶだけでプロの音に。
音量を整える
コンプレッサーで音量のばらつきを整え、Spotify・YouTube・Apple Podcasts の基準に自動でラウドネス正規化。聞きやすく、プラットフォームに最適な音量へ。
不要部分をカット
2秒以上の無音を自動検出してカット。波形を見ながらの手動トリム&フェードも。自然な仕上がりに余白500msを残します。
文字起こし(Whisper)
OpenAI Whisper をブラウザ内で実行。日本語・英語に対応し、SRT/VTT/TXT で書き出し。結果からワンクリックで該当区間をカットできます。
ボイス生成(ベータ)
Chatterbox をブラウザ内で実行し、10〜20秒のリファレンス音声から声質をクローン。テキストから自然な音声を生成し、そのまま EQ で仕上げて書き出せます。
高品質エクスポート
MP3(最大320kbps)またはWAVで出力。複数ファイルをまとめて処理&一括ダウンロード。
ビフォー・アフター比較
処理前と処理後をワンクリックで切り替えて聞き比べ。仕上がりを耳で確認できる。
制限なし・完全無料
ファイルサイズ・回数の制限なし。透かしなし。商用利用OK。ずっと無料。
プライバシーファースト
サーバー転送なし
ファイルは一切サーバーに送信されません。すべての処理はブラウザ内で完結。
ローカル処理
音声処理は Web Audio API、文字起こしは WebGPU/Whisper、ボイス生成は Chatterbox をブラウザ内で実行。初回モデル取得後はインターネット接続すら不要。
アカウント不要
ログインもサインアップも不要。URLを開くだけで使えます。
よくある質問
AudioBuff は無料ですか?
はい、完全無料で利用できます。アカウント登録もクレジットカードも不要です。商用利用も可能です。
音声ファイルはサーバーにアップロードされますか?
いいえ。すべての処理はブラウザ内で完結し、ファイルがサーバーに送信されることは一切ありません。プライバシーを完全に保護します。
対応しているファイル形式は?
入力: MP3・WAV・OGG・FLAC・AAC・MP4。出力: 音声は MP3(最大 320kbps)または WAV、文字起こしは SRT・VTT・TXT で書き出せます。
文字起こしはどう動きますか?
OpenAI の Whisper モデルをブラウザ内で実行します。初回のみモデルをダウンロードしてキャッシュし、以降はオフラインでも使えます。音声はサーバーに送信されません。
文字起こしの対応言語は?精度は?
日本語と英語に対応しています。精度は素材の音質・話速に依存しますが、標準モデル(Whisper tiny 相当)と高精度モデル(base 相当)から選べます。WebGPU が使える環境ではさらに高速に動きます。
文字起こし結果から不要な部分をカットできますか?
はい。文字起こし結果の各セグメントに✂ボタンがあり、ワンクリックで該当区間を書き出し時に除外できます。「えーと」やフィラーの削除に便利です。
ボイス生成はどのように動作しますか?
Resemble AI の Chatterbox モデルをブラウザ内で実行します。10〜20秒のリファレンス音声から声質をクローンし、テキストから音声を生成します。モデルは初回のみダウンロード(約2GB)してキャッシュされ、以降はオフラインで利用可能。音声もテキストもサーバーには送信されません。
ボイス生成の対応言語と注意点は?
現在は英語のみ対応です(ベータ版)。生成音声には Resemble Perth ウォーターマークが常時埋め込まれ、AI 生成音声であることを後から検証できます。倫理的な利用のため、本人または明示的な許諾を得た音声のみを使用してください。
EQ(イコライザー)って何ですか?
音の各周波数帯域のバランスを調整するツールです。こもった声をクリアにしたり、低音の厚みを出したりできます。プリセットを選ぶだけで自動的に設定が適用されるので、専門知識は不要です。
スマートフォンでも使えますか?
はい、モバイルブラウザに対応しています。iPhone・Android のどちらでもお使いいただけます。
どんな用途に使えますか?
ポッドキャスト、音楽、動画ナレーション、ボイスメモ、配信音声など、あらゆる音声コンテンツの仕上げに使えます。
今すぐ、音を磨こう。
ダウンロード不要。アカウント不要。